Inequality, Rebellion, and a Reconsideration of an Old Analysis (i.e. Students: You Can Do This, and Do This Better)

- Ho Chi Minh City, by another name, in another life. (New Naratif)
I am teaching a quantitative methods class for students in international relations, which presents its own assorted challenges. Beyond the general apprehension that social science students have to statistics, a class like the one I teach is 1) the last students take before writing their BA theses and 2) by far the most unusual class students will have taken to this point, all things considered. Students don’t get a lot of quantitative things thrown at them by the point they have to deal with me. Add in the fact that each given class at the BA level is about a month long and about four hours a week, and there is a multifaceted tension of communicating why the material is important and how you can do it while condensing 2/3rds of what I’d like to discuss into about a third of the time I’d have in a normal American semester. It’s a challenge.
One thing that I think might help students is teaching around replication. I’ve taken to doing this elsewhere, where I can. However, replication of simple linear models can only go so far when those simple linear models still require the kind of data creation skills that a student cannot plausibly get in a month. For example, we should all thank Joshua Alley for curating an archive of data sets that replicate simple cross-sectional linear models. However, even Appel and Loyle (2012) and Kono (2006) might be above what students can do themselves in a month with the limited time I have to teach them about things. Thus, a resource like that is great for teaching the methods, less so if there is an expectation that students can take some initiative and do something similar on their own.
Thus, I’ve started scanning old journals in political science and international relations for some inspiration. Based on my experience discovering an old (and to be blunt: quite bad) article from Newhouse (1977) some years ago, it’s sometimes the case that quantitative articles that are more than 40 years old come with the data set included as a table in the article. It would be a pipe dream to expect replication data that old to be on Dataverse (or even ICPSR’s repository), but the relative infancy of statistical modeling in the social sciences means the models are simple and the data sets themselves are simple. Thus, the data are sometimes included in the article itself. It’s why the forthcoming version 1.4.0 of {stevedata} has some data sets I’ve found recently. Parvin (1973) includes all variables in his simple linear model in the appendix at the end of the article. It takes some trial and error to figure out what exactly Parvin is doing in his analysis, but that becomes part of the learning experience for students. It’ll also help with instruction by way of what logarithmic transformations are actually doing.
Likewise, Mitchell (1968) [ungated] has all his variables as Table 1 in his article. There’s a lot to like in what Mitchell (1968) is doing, and it’s why I’ll discuss it here. With what limited time students have in a course like ours at Stockholm University, I think they can come away with the confidence that 1) they can do something like this too and 2) they can do it better. In fact, there is a lot that Mitchell (1968) is openly doing wrong that the student won’t get wrong with the benefit of modern technology.
First, here are the R packages I’ll be using in this post.
library(tidyverse)
library(stevedata) # forthcoming, v. 1.4 on Github
library(kableExtra)
library(modelsummary)
library(stevethemes)
library(ggrepel)
library(modelr)
Here’s a table of contents.
- What’s Mitchell (1968) Doing (and Why)?
- Mitchell’s Linear Model, and What’s Wrong
- Mitchell’s Scatterplots, and What’s Wrong
- So Why Do This?
What’s Mitchell (1968) Doing (and Why)?
It’s good to read the full article to get an understanding of what the author is trying to do and what’s at stake in a quantitative analysis. Briefly, the policy backdrop of this particular article is clearly the ongoing war in Vietnam, but the academic backdrop concerns two recent articles by Russett (1964) and Feierabend and Feierabend (1966) about the relationship between inequality and violence. What is the relationship between inequality (as a cause) and violence (as an effect)? Russett (1964) and Feierabend and Feirabend (1966) report a positive relationship in a cross-national context. Higher inequality -> higher levels of violence, however measured. Mitchell (1968) wants to see what this looks like at a subnational level, and in the then-timely context of South Vietnam. The argument, the extent to which he has one, is couched as a competitive hypothesis test. Either higher inequality leads to higher violence, or lower violence. There isn’t really a null hypothesis offered.
Mitchell’s analysis takes the 26 provinces of South Vietnam (his unit of analysis) and measures not necessarily “violence”, but “rebellion” or “insurgency” by the absence of it. His primary dependent variable is the extent of control (as a percentage) of the province by the South Vietnamese government. Higher values = less rebellion. Lower values = more rebellion, or more violent contestation without clear control by the South Vietnamese government. His independent variables are multiple and I will have to refer the reader to a close scrutiny of what he’s doing to understand it in greater detail. No matter, the independent variables Mitchell (1968) selects are the result of a stepwise regression procedure to isolate the variables that are all significantly associated with the dependent variable.1 These are:
- Owner-operated land: a percentage of land ownership in the province. 100 = complete land ownership. 0 = universal tenancy where South Vietnamese peasants work on land they do not own. Higher values = more equality.
- Coefficient of variation of the distribution of land-holdings, by size: this is a clunky way of saying “standard deviation of land-holding size, divided over the mean land-holding size.” If every landholding is of equal size, the observation is 0. Larger values suggest more variability in size of land-holdings with the implication being larger land-holdings are conspicuous in the province. Higher values = more inequality.
- French land, subject to transfer: a percentage, this (and the Vietnamese equivalent referenced below) refers to a particular ordinance (“Ordinance 57”) in South Vietnam that sought to redistribute estates over a particular size. It is nice that reading Mitchell (1968) informs a bit of context here. Supposedly, French land subject to transfer and redistribution was simply expropriated (at this time) by the South Vietnamese government. Thus, the more land the South Vietnamese government seized that was French, the more it held for itself. Higher values = more inequality.
- Vietnamese land, subject to transfer: another percentage by way of the same ordinance (see above), the Vietnamese equivalent refers to land both expropriated by the South Vietnamese government and redistributed. The logic is the Vietnamese version suggests higher values = lower inequality since the measure (partly) includes redistributed land.2
- Mobility: a measure of the average degree of accessibility within a province (by reference to the percentage of the province that is plains and hills without dense forests). I’m disinclined to think of this measure as one of “inequality”, but Mitchell (1968, 436) wants to read it as one.
- Population density: a simple measure of provincial population, per square kilometer.
Because we’re talking about just 26 observations with only a select few variables, this becomes Table 1 in the article itself.
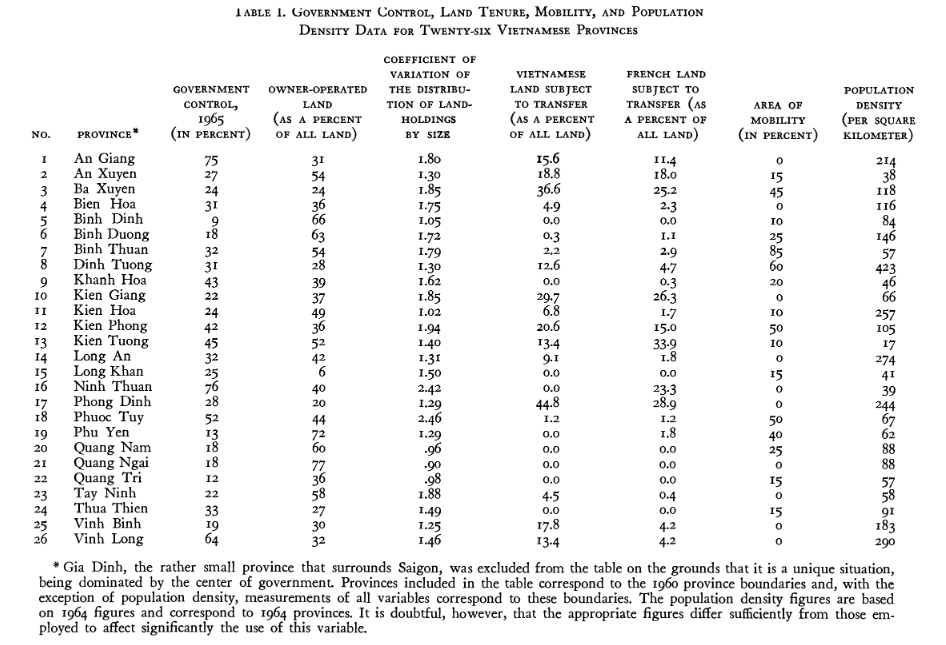
- Mitchell's (1968) data set, as Table 1 in his article.
I have these data scraped from his Table 1 as Mitchell68 in {stevedata}.
Mitchell68
#> # A tibble: 26 × 9
#> id province gc ool cvlhs vl fl m pd
#> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 An Giang 75 31 1.8 15.6 11.4 0 214
#> 2 2 An Xuyen 27 54 1.3 18.8 18 15 38
#> 3 3 Ba Xuyen 24 24 1.85 36.6 25.2 45 118
#> 4 4 Bien Hoa 31 36 1.75 4.9 2.3 0 116
#> 5 5 Binh Dinh 9 66 1.05 0 0 10 84
#> 6 6 Binh Duong 18 63 1.72 0.3 1.1 25 146
#> 7 7 Binh Thuan 32 54 1.79 2.2 2.9 85 57
#> 8 8 Dinh Tuong 31 28 1.3 12.6 4.7 60 423
#> 9 9 Khanh Hoa 43 39 1.62 0 0.3 20 46
#> 10 10 Kien Giang 22 37 1.85 29.7 26.3 0 66
#> # ℹ 16 more rows
A fancier version that displays the full contents follows, by way of {kableExtra}.
| No. | Province | Govt. Control | Owner-Operated Land | Coefificient of Variation in Land-Holdings | Vietnamese Land, Subject to Transfer | French Land, Subject to Transfer | Mobility | Population Density |
|---|---|---|---|---|---|---|---|---|
| 1 | An Giang | 75 | 31 | 1.80 | 15.6 | 11.4 | 0 | 214 |
| 2 | An Xuyen | 27 | 54 | 1.30 | 18.8 | 18.0 | 15 | 38 |
| 3 | Ba Xuyen | 24 | 24 | 1.85 | 36.6 | 25.2 | 45 | 118 |
| 4 | Bien Hoa | 31 | 36 | 1.75 | 4.9 | 2.3 | 0 | 116 |
| 5 | Binh Dinh | 9 | 66 | 1.05 | 0.0 | 0.0 | 10 | 84 |
| 6 | Binh Duong | 18 | 63 | 1.72 | 0.3 | 1.1 | 25 | 146 |
| 7 | Binh Thuan | 32 | 54 | 1.79 | 2.2 | 2.9 | 85 | 57 |
| 8 | Dinh Tuong | 31 | 28 | 1.30 | 12.6 | 4.7 | 60 | 423 |
| 9 | Khanh Hoa | 43 | 39 | 1.62 | 0.0 | 0.3 | 20 | 46 |
| 10 | Kien Giang | 22 | 37 | 1.85 | 29.7 | 26.3 | 0 | 66 |
| 11 | Kien Hoa | 24 | 49 | 1.02 | 6.8 | 1.7 | 10 | 257 |
| 12 | Kien Phong | 42 | 36 | 1.94 | 20.6 | 15.0 | 50 | 105 |
| 13 | Kien Tuong | 45 | 52 | 1.40 | 13.4 | 33.9 | 10 | 17 |
| 14 | Long An | 32 | 42 | 1.31 | 9.1 | 1.8 | 0 | 274 |
| 15 | Long Khan | 25 | 6 | 1.50 | 0.0 | 0.0 | 15 | 41 |
| 16 | Ninh Thuan | 76 | 40 | 2.42 | 0.0 | 23.3 | 0 | 39 |
| 17 | Phong Dinh | 28 | 20 | 1.29 | 44.8 | 28.9 | 0 | 244 |
| 18 | Phuoc Tuy | 52 | 44 | 2.46 | 1.2 | 1.2 | 50 | 67 |
| 19 | Phu Yen | 13 | 72 | 1.29 | 0.0 | 1.8 | 40 | 62 |
| 20 | Quang Nam | 18 | 60 | 0.96 | 0.0 | 0.0 | 25 | 88 |
| 21 | Quang Ngai | 18 | 77 | 0.90 | 0.0 | 0.0 | 0 | 88 |
| 22 | Quang Tri | 12 | 36 | 0.98 | 0.0 | 0.0 | 15 | 57 |
| 23 | Tay Ninh | 22 | 58 | 1.88 | 4.5 | 0.4 | 0 | 58 |
| 24 | Thua Thien | 33 | 27 | 1.49 | 0.0 | 0.0 | 15 | 91 |
| 25 | Vinh Binh | 19 | 30 | 1.25 | 17.8 | 4.2 | 0 | 183 |
| 26 | Vinh Long | 64 | 32 | 1.46 | 13.4 | 4.2 | 0 | 290 |
With the data at hand, it takes next to no effort to do Mitchell’s (1968) analysis as he says he did.
Mitchell’s Linear Model, and What’s Wrong
Mitchell (1968, 432) reports the results of his statistical model in a way I would not encourage, in addition to advertising the stepwise procedure that informed the design.
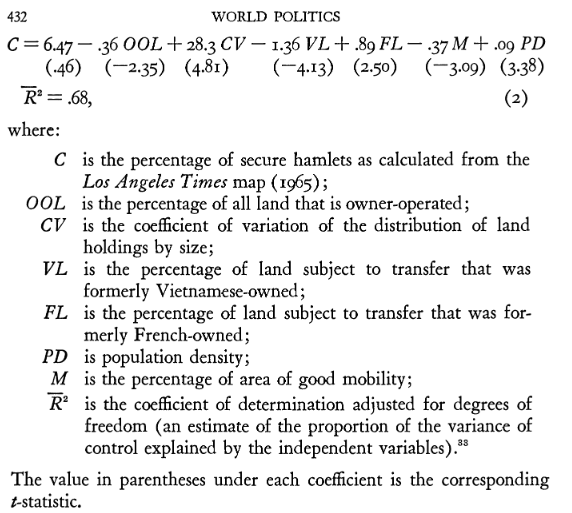
- The core regression results that Mitchell (1968, 432) reports.
If you were to do this yourself, you’d get something a bit different.
M1 <- lm(gc ~ ool + cvlhs + vl + fl + m + pd, Mitchell68)
summary(M1)
#>
#> Call:
#> lm(formula = gc ~ ool + cvlhs + vl + fl + m + pd, data = Mitchell68)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -18.899 -5.642 -2.292 7.193 25.559
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -6.02986 16.26457 -0.371 0.71494
#> ool -0.18938 0.17342 -1.092 0.28848
#> cvlhs 25.60708 6.96066 3.679 0.00159 **
#> vl -1.09422 0.38105 -2.872 0.00977 **
#> fl 1.11983 0.40966 2.734 0.01320 *
#> m -0.13710 0.11164 -1.228 0.23442
#> pd 0.09137 0.03036 3.010 0.00721 **
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 12.07 on 19 degrees of freedom
#> Multiple R-squared: 0.6568, Adjusted R-squared: 0.5484
#> F-statistic: 6.059 on 6 and 19 DF, p-value: 0.001114
That can’t go unnoticed. In fact, it did not go unnoticed by Paranzino (1972, 567) in his critique of this paper. If Mitchell did what he said he did, the above R code console output would’ve been the results he’d report. If the stepwise selection procedure is what Mitchell (1968) said he used for variable selection, the insignificant results for the mobility and owner-operated land variables would betray that. In fact, we’re at a loss as to how this happened. It’s one thing to note that the intercept is slightly off, or that the population density variable should have a t-value of 3.01 (and not 3.38). Discrepancies like that would stand out, but might be charitably attributed to a transcription error or some kind of generous rounding happening at multiple levels. However, what Mitchell (1968) says he did to inform his design strategy, what he says he used as his data, and what estimation procedure he says he used are betrayed by what he ultimately presents. The proof is right there in Table 1 if you were to do this yourself.
I can’t speak for the technology of the time, nor what might have got lost or jumbled in transcription. No matter, students can do this, but do it better. Let {modelsummary} help you.
modelsummary(list("Model 1" = M1),
title = "The Correlates of Govt. Control of South Vietnamese Provinces, 1965",
stars = c("***" = .01,
"**" = .05,
"*" = .1),
output = 'kableExtra',
gof_map = c("nobs", "r.squared", "adj.r.squared"),
coef_map = c("ool" = "Owner-Operated Land (%)",
"cvlhs" = "Coefficient of Variation in Land-Holding Size",
"vl" = "Vietnamese Land, Subject to Transfer (%)",
"fl" = "French Land, Subject to Transfer (%)",
"m" = "Area of Mobility (%)",
"pd" = "Population Density",
"(Intercept)" = "Intercept"),
)
| Model 1 | |
|---|---|
| Owner-Operated Land (%) | −0.189 |
| (0.173) | |
| Coefficient of Variation in Land-Holding Size | 25.607*** |
| (6.961) | |
| Vietnamese Land, Subject to Transfer (%) | −1.094*** |
| (0.381) | |
| French Land, Subject to Transfer (%) | 1.120** |
| (0.410) | |
| Area of Mobility (%) | −0.137 |
| (0.112) | |
| Population Density | 0.091*** |
| (0.030) | |
| Intercept | −6.030 |
| (16.265) | |
| Num.Obs. | 26 |
| R2 | 0.657 |
| R2 Adj. | 0.548 |
| * p < 0.1, ** p < 0.05, *** p < 0.01 |
You don’t have to get something wrong in transcription when you have the technology to do it for you. Since I can’t impute motives for Mitchell (1968), I can only really say what he presents is wrong. It’s not clear what went wrong, but something went wrong.3 I think my students can do better with the resources they have.
Mitchell’s Scatterplots, and What’s Wrong
After (misre)presenting the results of the linear model, Mitchell turns his attention to some quantities of interest implied by the results of his model. Take, for example, his Figure 1 on p. 433.
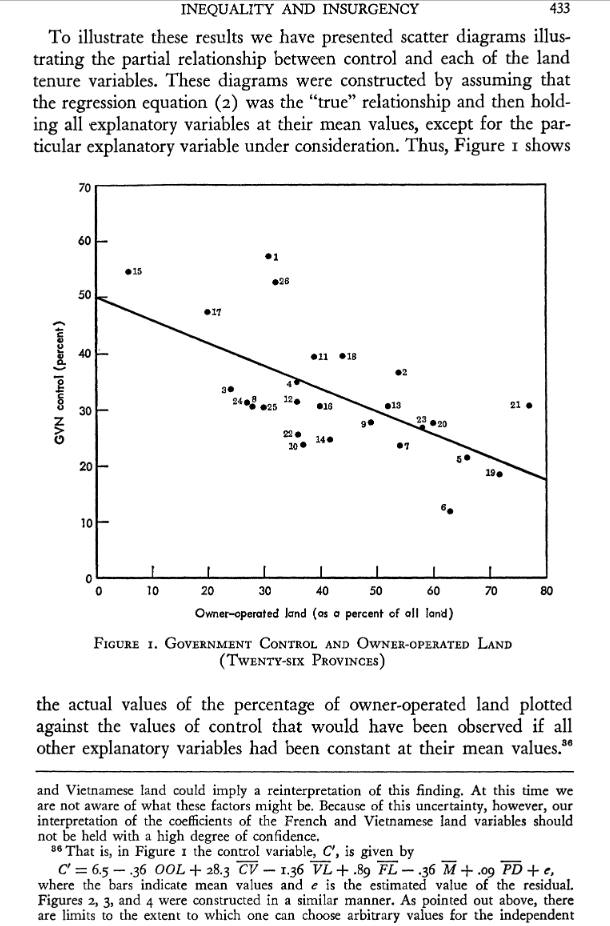
- Figure 1 in Mitchell (1968), with some added context.
Ignore, for the moment, that Mitchell (1968) is reiterating a significant effect for the owner-operated land variable where there in fact is none. Further: ignore, for the moment, that Mitchell’s fn. 36 contains a formula that is not identical to the formula he reports in the regression results above (his Equation 2). Look at the scatterplot and the numbers attached to the assorted coordinates. These coincide with the numeric identifiers for the particular province. If Mitchell (1968) was doing what he said he was doing, the results of the plot would look something like this.
Mitchell68 %>%
mutate(resid = resid(M1),
expected = 6.5 - (.36*ool) + 28.3*(mean(cvlhs)) - 1.36*(mean(vl)) +
.89*(mean(fl)) - .36*(mean(m)) + .09*(mean(pd)) + resid) %>%
ggplot(.,aes(ool, expected)) + geom_point() + geom_smooth(method = 'lm') +
theme_steve() +
geom_text_repel(aes(label = id)) +
scale_y_continuous(labels = scales::percent_format(scale = 1)) +
scale_x_continuous(labels = scales::percent_format(scale = 1)) +
labs(title = "The Supposed Partial Relationship Between Owner-Operated Land and Government Control",
subtitle = "Figure 1 in Mitchell (1968) does not square with what this should look like.",
x = "Owner-Operated Land (as a Percentage of All Land)",
y = "South Vietnamese Government Control (Percent, Expected)",
caption = "Data: Mitchell (1968), by way of Mitchell68 in {stevedata}.")
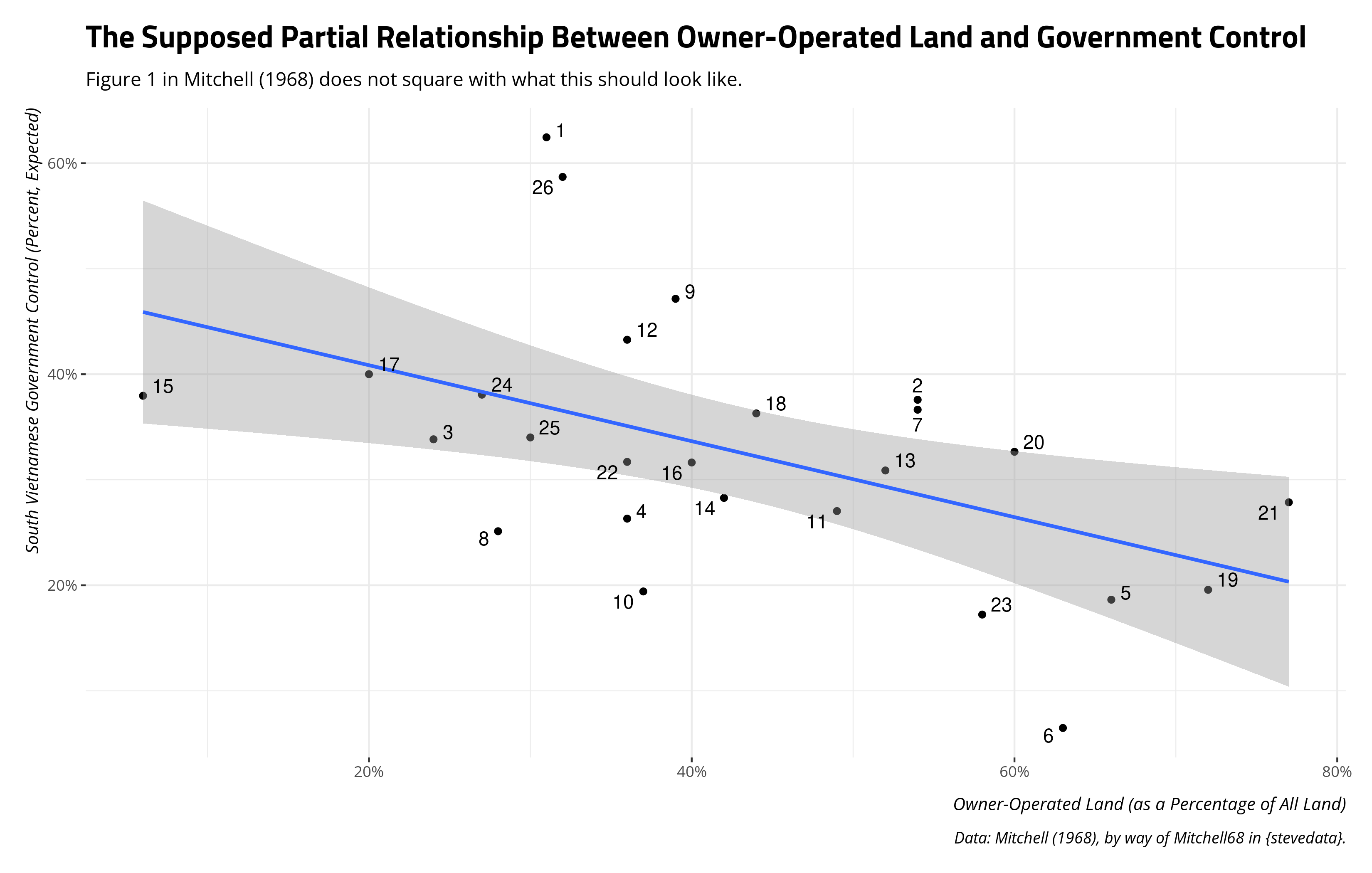
Notice that the first province (Province 1, or An Giang) should be estimated above 60% and not just below it. Mitchell (1968) wants to estimate an expected value for Province 15 (Long Khan) to be around 55% when it should be around 38%. There should be much greater separation between the 22nd province (Quang Tri) and the 10th province (Ken Giang) than there is in Figure 1. The second province (An Xuyen) and and seventh province (Bin Thuan) should be right on top of each other as well. Yet, Mitchell’s (1968) Figure 1 wants to imply a near 20 percentage point difference between the two expected observations. There are countless other discrepancies as well, which all extend to the other scatterplots Mitchell (1968) presents in his analysis. It is the case that we don’t have access to Mitchell’s (1968) residuals, and our residuals are having to do the work of the understudy. But, we’ve also blown past a few failures by this point to be here.
It’s worth saying that you really shouldn’t be doing it this way. In the benign interpretation that something got lost in transcription with the less automatic ways in which figures were constructed at that time (i.e. by hand), you could take even more of the guesswork and room for error out by having R calculate this for you. Let data_grid() in the {modelr} package guide you.
data_grid() is going to take the data (Mitchell68) and an optional argument of the model (.model = M1). By default, it will return the median for all observations in the data frame that are included as independent variables in the model. It will, however, allow you to adjust one (or more) of these variables. Here, a la Figure 1, we’re adjusting the owner-operated land variable (ool) to be a sequence from 0 to 80 by (default) increments of 1. This will create a new data frame (newdat) that is a hypothetical prediction grid, a la what Mitchell (1968, 433) says he’s doing.
Mitchell68 %>%
data_grid(.model = M1,
ool = seq(0,80)) -> newdat
newdat
#> # A tibble: 81 × 6
#> ool cvlhs vl fl m pd
#> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0 1.48 4.7 2.05 12.5 88
#> 2 1 1.48 4.7 2.05 12.5 88
#> 3 2 1.48 4.7 2.05 12.5 88
#> 4 3 1.48 4.7 2.05 12.5 88
#> 5 4 1.48 4.7 2.05 12.5 88
#> 6 5 1.48 4.7 2.05 12.5 88
#> 7 6 1.48 4.7 2.05 12.5 88
#> 8 7 1.48 4.7 2.05 12.5 88
#> 9 8 1.48 4.7 2.05 12.5 88
#> 10 9 1.48 4.7 2.05 12.5 88
#> # ℹ 71 more rows
Next, we’re going to use the predict() function to create model predictions (preds) based on the model (M1) and the hypothetical prediction grid (newdat). Why do it by hand when predict() will do it for you? We’ll optionally ask for a 90% confidence interval (interval = "confidence", level = .9) as an upper and lower bound of the predicted value of y (here: government control).
preds <- predict(M1, newdata = newdat,
interval = "confidence",
level = .9) %>% as_tibble()
preds
#> # A tibble: 81 × 3
#> fit lwr upr
#> <dbl> <dbl> <dbl>
#> 1 35.2 20.5 49.9
#> 2 35.0 20.6 49.5
#> 3 34.8 20.7 49.0
#> 4 34.7 20.8 48.5
#> 5 34.5 20.9 48.1
#> 6 34.3 21.0 47.6
#> 7 34.1 21.0 47.1
#> 8 33.9 21.1 46.7
#> 9 33.7 21.2 46.2
#> 10 33.5 21.3 45.8
#> # ℹ 71 more rows
Now, let’s visualize what Mitchell (1968) was trying to communicate, using his data (but the actual results). Yes, there are some advanced hacks happening here in the ggplot() function to have two different data sets speak to each other, though the particulars of what’s happening here for presentation can be inferred with an eagle eye. I don’t expect the student to fully understand all what’s happening here in the code creating the plot at first glance, but I do expect an awareness of what’s happening with respect to what Mitchell (1968) is doing.
preds %>%
bind_cols(newdat, .) %>%
rename(gc = fit) %>% # rename for convenience sake; you'll see why later
ggplot(.,aes(ool, gc, ymin=lwr, ymax=upr)) +
geom_ribbon(alpha = .2, color='black', fill = g_c("su_blue")) +
geom_line() +
# Let's bring back in the actual coordinates from Mitchell (1968).
# whereas `lwr` and `upr` do not exist in these data, we have to specify them as such.
geom_point(data = Mitchell68,
aes(x = ool, y = gc, ymin=NULL, ymax=NULL)) +
theme_steve() +
geom_text_repel(data = Mitchell68,
aes(label = id, ymin = NULL, ymax = NULL)) +
scale_y_continuous(labels = scales::percent_format(scale = 1)) +
scale_x_continuous(labels = scales::percent_format(scale = 1)) +
labs(title = "The Actual Partial Relationship Between Owner-Operated Land and Government Control",
subtitle = "Here's a better, more accurate way of communicating what Mitchell (1968) is wanting to do.",
x = "Owner-Operated Land (as a Percentage of All Land)",
y = "South Vietnamese Government Control (Percent, Expected)",
caption = "Data: Mitchell (1968), by way of Mitchell68 in {stevedata}.")
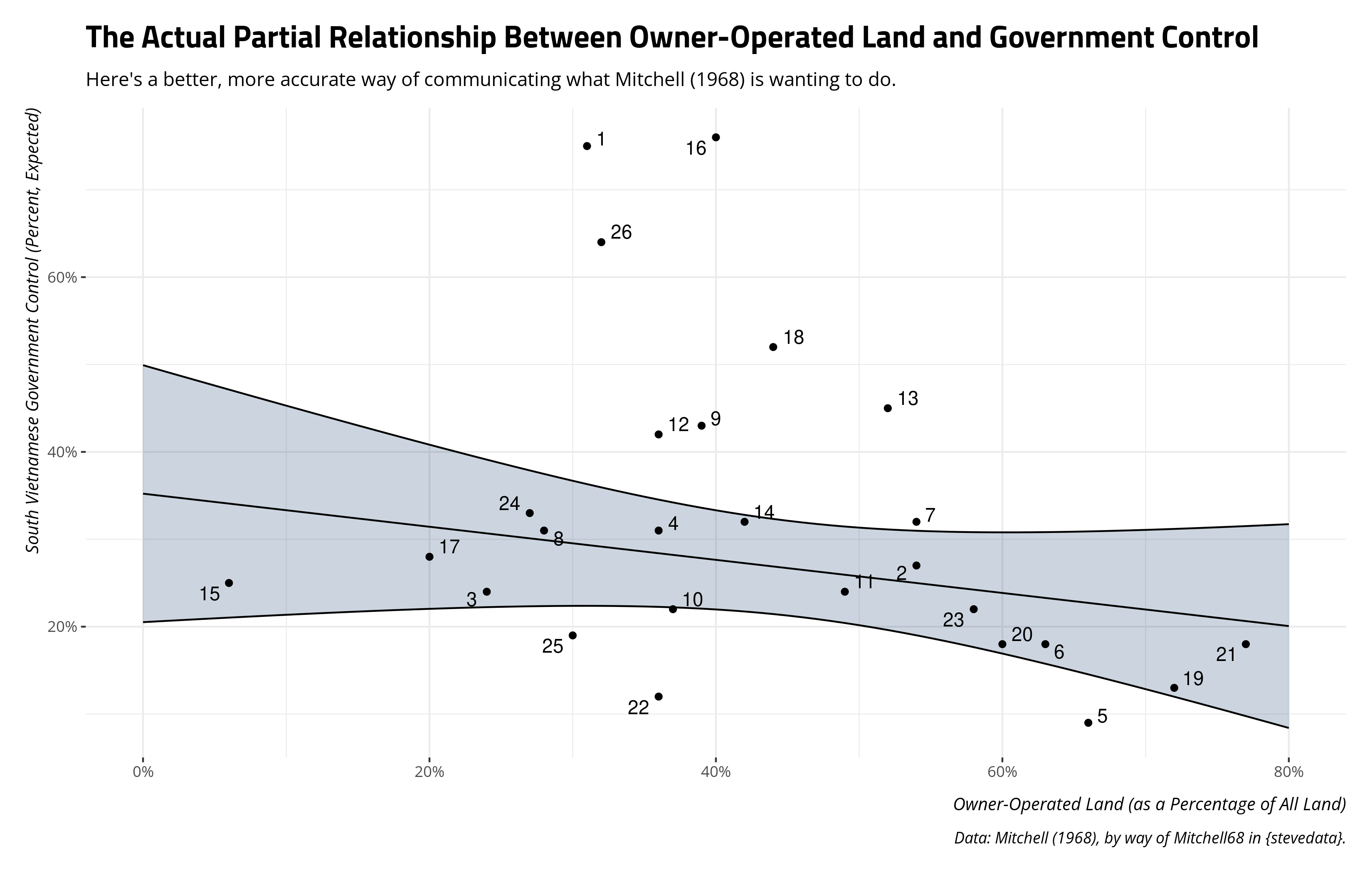
Contrast this plot with either Figure 1 in Mitchell (1968) or the initial approximation of it. If we follow Mitchell’s (1968) approach, the min-max effect of the owner-operated land variable across this proposed range is a reduction of about 30 percentage points in the dependent variable. The coordinates supplied are not what the actual observations are, but what they are expected to be. If, however, we draw an actual line across this proposed range using the actual results and show the actual coordinates, the results look quite different. We instead see that the min-max effect is a difference of just 15 percentage points. Importantly, the lower bound where the owner-operated land variable is 0 is greater than the estimate for when the owner-operated land variable is its proposed maximum of 80 (let alone what the upper bound for that effect is). There isn’t much of an effect at all, and this plot shows the actual results and actual fitted values map poorly to what is observed in the data that Mitchell (1968) makes available.
So Why Do This?
This article is 56 years old and concerns the analysis of a state that has not existed since 1975. Why are we doing this?
I don’t offer this as a means of chastising a failure to replicate, though I’m grateful the data are provided that allow such an opportunity. Instead, I offer this article (and this accompanying post) to my BA students with the belief that they could do something like this. Say what you will about what Mitchell is doing, and certainly Paige (1970) and Paranzino (1972) have plenty to say on that. For an undergraduate learning quantitative methods for the first time, I think you can do this. Mitchell (1968) may have done this at a particular time where data we take for granted were still in their infancy and computation on even simple models took time.4 Students have a plethora of data around them now and computation takes fractions of a second. This does not discount the work that Mitchell (1968) invested in harvesting maps from the Los Angeles Times or archival data on land-holdings in South Vietnam. In fact there’s an appreciation of it. Perhaps students do not have the time for that, but they do have the time to think about a topic like this and grab data that are more plentiful and readily accessible than what Mitchell had at his immediate disposal.
Again, say what you will about what Mitchell’s final product, but the question is set up rather nicely. He’s clear about what he’s doing and why he’s doing it. His design also shows a clever attention to identification concerns when he makes sure all his independent variables are observed prior to the referent year. I might want undergraduates to better review scholarship than Mitchell does, and to better set up the theoretical mechanisms that underpin a competitive hypothesis test like his. That transfers to students I teach today. Mitchell is also getting a lot of things wrong and engaging in statistical practices that would get you laughed out the room these days.5 However, I’d be quite happy if an undergraduate set up a simple model like this. Perhaps it’s weird to say a publication in one of the most prestigious IR journals (World Politics) over 50 years ago would be about what I should expect of an undergraduate today, but that’s the nature of the business.
I also offer this to my students with the firm conviction that you can do this better than he did. Students have tools at their disposal that would avoid many of the errors that Mitchell (1968) appears to communicate in this analysis. There’s no mistaking what the results of lm() will tell you in R. There’s no clumsiness you should impose on yourself drawing graphs by hand. There’s no real need to commit errors in hand calculations when R can do this all for you. Again, that’s not to chastise Mitchell (1968) any more than I have to this point. Students have the ability to answer their questions with more confidence and less opportunity for mistakes than Mitchell (1968) had. Students just have to do what Mitchell (to his credit) did well. Think of a question that can be explored with quantitative methods. Think through measures of the dependent variable and independent variables, and what the measures mean for the concepts at hand. Use what you know/are learning in R to start exploring these relationships that interest you. You can do it; you just have to get going.
-
This was such a curious ritual of its time and it’s worth emphasizing you should not ever do this as a design strategy. Mitchell’s (1968, 424) use of it, and defense of it, would be an automatic rejection at any quantitatively oriented journal today. I suppose one superlative of Mitchell’s (1968) design is that he cites a textbook work that seems to encourage this practice. Perhaps, then, we can understand this citation as a kind of patient zero. ↩
-
This logic is interesting but questionable, and we’ll just have to roll with the premise for the nature of the intended use of these data. If an undergrad did this, I’d make a note of it but wouldn’t deduct points. It’s at least novel and reasonably argued, which is why I would laud an undergraduate taking such initiative. ↩
-
Having only a passing familiarity with technology of the time, it’s possible some chicanery came with a punched card. It wouldn’t be the first time I’ve heard tell of such issues involving a punched card tabulator. Stories about those get around from those old enough to tell them. ↩
-
We take the concept of “gross domestic product” for granted, but its modern formulation would’ve been just over 30 years old by this time. The ability to marshal data on global scale for it would’ve been about 20 years old by time Mitchell was working on his analysis. ↩
-
Don’t think I didn’t see that 33rd footnote discussing R-square. Oh, I noticed. ↩
Disqus is great for comments/feedback but I had no idea it came with these gaudy ads.