An Empirical Analysis of RuPaul's Drag Race Contestants

- Kameron Michaels, the people's champion of Season 10, isn't quite sure what's happening below but is revolted at the sight of it.
Last updated: 9 May 2022. Coverage includes Season 14.
My wife got me hooked into watching RuPaul’s Drag Race with her. The long and short of it is I didn’t need to have my arm twisted to watch or enjoy the show. Indeed, drag nights at Icon in Tuscaloosa—incidentally home to the performer who gave Trinity her “Tuck” moniker—are some of my fondest memories of graduate school. A performer who routinely served as opening act for her—and sadly passed away last year—was among the sweetest/kindest people I knew in town.1 I had a receptiveness to drag as concept and creative outlet, but oddly did not know about the show until my wife told me about it.
My wife also informed me of the debates that fans have about the show, some of which can be quite heated. Several of these—at least the ones that aren’t completely subjective or involve questions that quickly devolve to total grease fires—involve concerns of measurement and ranking. Certainly, the show has evolved from Season 1 to Season 10, but how would a fan rank, say, Jinkx Monsoon’s run to the crown in Season 5 versus Bianca Del Rio in Season 6? Or Bob the Drag Queen in Season 8?
This creates a lot of conversation on the subreddit for the show and spawns numerous videos where fans can upvote or downvote a particular performer or carry on these debates. I hear it as an opportunity to scrape the wiki for the show and create a few data sets to see if I can measure these things myself. Toward that end, I created a package in R ({dragracer}), now on CRAN, that will contain various data sets for this. Mostly, I just wanted to call dibs on having an R package for the show named {dragracer}.
Here’s a table of contents for this post, especially if you want to jump past the data/methods section and into the 🔥 takes.
- About the Data/Methods
- An Empirical Analysis of RuPaul’s Drag Race Performances
- Conclusion: As 🔥 Takes
About the Data/Methods
The data package is a work in progress and leans heavily on scraping the wiki, especially the contestant-level information that the wiki turns into pyramidal tables. I have, so far, three data sets in the package. rpdr_contep is contestant-episode-level data about how contestants fared, if they appeared, in episodes as the season progressed. rpdr_contestants is contestant-level data that includes some background information on the contestants along with metrics of their performances through the season. rpdr_ep contains some episode-level data that would have been difficult or tedious to build into the contestant-episode-level data. These are data points like the mini-challenge winners, the runway theme (where applicable), and some information about the lip-sync.
There are some additional caveats.
- I interpret “HIGH TEAM” codings in the wiki as cases where the contestant was on a winning team for a main challenge, but the contestant herself is safe.
- “Eliminations” are broadly understood as cases where a participant was removed from the show. As a result, there is an
outcomevariable that codes whether a contestant was a winner, scored high, was safe, scored low, or was in the bottom two for the main challenge and runway and a corollaryeliminatedvariable if the contestant was removed from the show. The overlap here is substantial, obviously. However, there are a few cases where a contestant was removed despite winning a challenge (Willam, Season 4) or scoring safe (Eureka O’Hara, Season 9) for some other reason. - The
minichalwcolumn in the contestant-episode data is mostly uninformative. I should delete it or better sync the episode-level data with it. - Finales are sui generis and users should not read too much into them. They also evolve substantially over the show’s 11 seasons. For example, the first three seasons had finales where the finale itself effectively had a bottom and, practically, an elimination. Seasons 4-8 had top threes (later top fours) where there was no “bottom” or elimination, just a crowning. Season 9 started the newer trend of having a top four and semifinal competition that leads to a lip-sync for the crown. Users who want to compare performers should subset out finales.
- Related: Seasons 6 through 8 have a
penultimatecolumn. These were episodes in which RuPaul whittled the top four to a top 3. They’re unique episodes in that no one was a bottom, but everyone lip-synced. This created three winners and one bottom/elimination. I code those episodes as such but encourage users to subset those out when comparing contestant performances. However, I do not do this Season 11. Therein, there was no winner, but a clear bottom two in the episode that sent Vanessa Vanjie Mateo home and put Brooke Lynn Hytes as the fourth semifinalist. - The episode-level data has a
numqueenscolumn that codes the number of participants who were active in the episode. There were several cases where RuPaul reintroduced a performer—or, in the case of Season 7, an entire damn cast—at the start of the episode. In more than a few cases, those reintroduced were eliminated the exact same episode. - Related to that: I code that episode in Season 7 as a case where Pearl and Trixie Mattel were joint winners.
- The finales for Season 9 and Season 10 are cases where the runner-up(s) (e.g. Peppermint, Season 9) scored high and those who lost the semifinals (e.g. Trinity Taylor, Season 9) were bottoms for that episode. Again, these are finales so the user should subset them out when comparing queens across different seasons.
- Season 13 is going to be a clear outlier in comparing across seasons. If you wanted to standardize and compare across seasons in an honest way, you should probably omit the first three episodes as “uncompetitive” or “specials.” My own interpretation is that a non-finale episode is “competitive” when there is a bottom-two lip-sync and someone could go home (even if it’s a double-shantay). I elect to not do that here, just for ease.
An Empirical Analysis of RuPaul’s Drag Race Performances
The data are far from perfect or complete, but they’re workable for an empirical analysis of contestant performance for all seasons of RuPaul’s Drag Race (excluding All-Stars, which would be a mess to standardize). Here, I’ll explore some of the best performers in the herstory of the show with some rudimentary metrics. Namely, which contestants had the highest percentage of competitive (i.e. non-special, but non-finale) episodes in which they won, or scored high/won? Which queens scored the highest on the “Dusted or Busted” scoring system? The data aren’t too hard to generate and require a few lines in {tidyverse}. The source code, along with version herstory, is available on the _source directory for my website.
Comparing the Season Winners
This will facilitate some kind of comparison, say, among the season-winners by reference to thier performance in main challenges/runways through the course of a season. I choose to focus on the percentage of wins, bottoms, etc. because the number of competitive episodes varies considerably through the 12 seasons. For example, Bebe Zahara Benet had just six episodes before the finale in which she could’ve been eliminated. Raja, Season’s 3 winner, had 12. Seasons since then have had 10 or 11 competitive episodes, excluding the eight competitive episodes in Season 8. Season 13 was particularly long.
| season | contestant | % Wins | % Wins/Highs | % Bottom | % Bottom/Low | D/B Score |
|---|---|---|---|---|---|---|
| S01 | BeBe Zahara Benet | 33.33% | 50% | 16.67% | 16.67% | 3 |
| S02 | Tyra Sanchez | 33.33% | 55.56% | 0% | 11.11% | 7 |
| S03 | Raja | 25% | 58.33% | 8.33% | 16.67% | 7 |
| S04 | Sharon Needles | 36.36% | 54.55% | 9.09% | 18.18% | 7 |
| S05 | Jinkx Monsoon | 18.18% | 81.82% | 9.09% | 9.09% | 9 |
| S06 | Bianca Del Rio | 30% | 70% | 0% | 0% | 10 |
| S07 | Violet Chachki | 27.27% | 45.45% | 0% | 18.18% | 6 |
| S08 | Bob the Drag Queen | 37.5% | 37.5% | 12.5% | 12.5% | 4 |
| S09 | Sasha Velour | 18.18% | 63.64% | 0% | 9.09% | 8 |
| S10 | Aquaria | 27.27% | 36.36% | 0% | 18.18% | 5 |
| S11 | Yvie Oddly | 7.69% | 30.77% | 7.69% | 15.38% | 2 |
| S12 | Jaida Essence Hall | 25% | 41.67% | 8.33% | 8.33% | 6 |
| S13 | Symone | 35.71% | 50% | 14.29% | 14.29% | 8 |
| S14 | Willow Pill | 7.14% | 7.14% | 14.29% | 14.29% | -2 |
The table won’t reveal too much that stands at odds with what long-running fans of the show already know. Sharon Needles had the most main challenge wins of any season-winner and, in my interpretation of the data, is tied with Shea Couleé (a Season 9 semifinalist) for most main challenge wins of any performer. Fans will qualify that Sharon won her challenges outright while Shea shared two of her wins with Sasha Velour. This may matter to the allocation of prize money but won’t matter in the data as I have it.
Perhaps the strongest contestants are in the middle two seasons. Jinkx Monsoon and Bianca Del Rio effectively dominated their seasons. Jinkx stands out in particular for winning or placing high in nine of her 11 competitive episodes. A “safe” in the season-opener and bottom-two performance in the last competitive episode of the season before the finale sandwiched a run of excellence in which she won or scored high. This is particularly impressive because, if you want to treat the show as something other than reality TV in which winners are determined by RuPaul’s discretion, her season might have been the most competitive. Roxxxy Andrews, Alaska, Detox, and Alyssa Edwards are legendary names as drag performers.
Likewise, Bianca Del Rio has the distinction of the first and, to date, only queen to never land in the bottom two or even get a “low” rating for a given episode. She is not alone as a winner to have never lip-synced for her life, but she is unique for not even ranking low. That effectively explains the one-point differential favoring Bianca Del Rio over Jinkx Monsoon in the “Dusted or Busted” scoring system.
Bob the Drag Queen and Aquaria stand out for scoring eye-openingly low in the “Dusted or Busted” scoring system. Both are, from what I’ve gathered, well-respected among fans of the show, and I think their low scores have some intuitive explanations. In Bob’s case, she had just eight competitive episodes in what amounts to a conspicuously abbreviated season. That she has 12% of her appearances in the bottom means she was in the bottom just once. Fans will remember that episode well. She lip-synced against Derrick Barry to the tune of one of my all-time favorite jams: Sylvester’s “You Make Me Feel (Mighty Real).” That contest was not close.
In Aquaria’s case, her season might have been the most competitive top to bottom in the show’s herstory. Blair St. Clair (9th place) and Mayhem Miller (10th place) could probably crack top five each in most other seasons. Vanessa Vanjie Mateo, 14th place in Season 10, may even make a long run in Season 11 (ed, May 31/2019: she did).
The conclusion of Season 11 and addition of Yvie Oddly to this list of winners means the current champion has surpassed BeBe Zahara Benet for lowest “Dusted or Busted” score to ever win a season. She has the fewest wins (1, and a shared one at that) and the fewest number of wins/highs (3) of any eventual champion. I can qualify that the episode prior to the reunion was one in which Yvie would’ve won if Ru had announced a winner. She had the best runway look (in a walk) and Ru named her first as a semifinalist. Alas, that episode is coded as a safe. Had Ru announced her as a winner that episode, her “Dusted or Busted” score improves to 4.
Comparing the Miss Congenialities (sic?)
I added an indicator to the contestant-episode data after season 12 noting which contestant was Miss Congeniality for the season. From there, we can compare the Miss Congenialities (sic?) across seasons.
| Season | Contestant | Rank | % Wins | % Wins/Highs | % Bottom | % Bottom/Low | D/B Score |
|---|---|---|---|---|---|---|---|
| S01 | Nina Flowers | 2 | 16.67% | 66.67% | 0% | 16.67% | 4 |
| S02 | Pandora Boxx | 5 | 0% | 50% | 12.5% | 25% | 1 |
| S03 | Yara Sofia | 4 | 8.33% | 41.67% | 16.67% | 33.33% | 0 |
| S04 | Latrice Royale | 4 | 18.18% | 36.36% | 27.27% | 36.36% | -1 |
| S05 | Ivy Winters | 7 | 12.5% | 37.5% | 12.5% | 37.5% | 0 |
| S06 | BenDeLaCreme | 5 | 20% | 60% | 20% | 30% | 3 |
| S07 | Katya | 5 | 18.18% | 54.55% | 18.18% | 18.18% | 4 |
| S08 | Cynthia Lee Fontaine | 10 | 0% | 0% | 33.33% | 33.33% | -2 |
| S09 | Valentina | 7 | 11.11% | 33.33% | 11.11% | 11.11% | 2 |
| S10 | Monét X Change | 6 | 0% | 40% | 30% | 30% | -2 |
| S11 | Nina West | 6 | 16.67% | 25% | 8.33% | 33.33% | 0 |
| S12 | Heidi N Closet | 5 | 10% | 30% | 40% | 50% | -5 |
| S13 | LaLa Ri | 10 | 16.67% | 16.67% | 33.33% | 50% | -3 |
| S14 | Kornbread (The Snack) Jete | 12 | 16.67% | 16.67% | 0% | 0% | 2 |
A few things stand out, which I’m sure I elaborate elsewhere later in this post because this is a newer addition to this post. The commentary here will also be ad hoc.
Nina Flowers has a special place in Drag Race herstory. It is highly unlikely that the show will ever have a second-place finisher who is also Miss Congeniality, given how the show is now structured. Her name also appears in the “robbed” list the extent to which she had a higher D/B score than the season’s winner.
Second, my modeling of the data is particularly sanguine about Katya and BenDeLaCreme and how good they were in their respective seasons. As it is, my simple item response model later in this post features them prominently in the list of top 25 performers in the show’s herstory, which is almost entirely comprised of season winners and runners-up. They are basically the lowest-ranked performers to appear in that top 25 list. Both were incidentally the Miss Congeniality winners for the season.
Finally, Heidi N Closet emerges as having the lowest D/B score among the Miss Congeniality winners. However, those who just watched the show know Heidi is a case of a performer gradually coming into her own as the season progressed and a case where metrics of season performance don’t capture how enjoyable she was. Yet, she spent half the season in the bottom two or with a low evaluation.
Who Were the Lowest-Ranked Performers to Land in the Top Four?
The data can also be used to identify the lowest-scoring performers to get a top four finish across all seasons. There are several metrics available for ranking these performers, but I’ll go in descending order, by “Dusted or Busted” score.
| season | rank | contestant | % Wins | % Wins/Highs | % Bottom | % Bottom/Low | D/B Score |
|---|---|---|---|---|---|---|---|
| S06 | 4 | Darienne Lake | 10% | 20% | 30% | 60% | -6 |
| S02 | 3 | Jujubee | 0% | 22.22% | 33.33% | 44.44% | -5 |
| S01 | 4 | Shannel | 0% | 16.67% | 33.33% | 50% | -4 |
| S05 | 4 | Detox | 9.09% | 18.18% | 27.27% | 36.36% | -4 |
| S14 | 3 | Daya Betty | 7.14% | 7.14% | 21.43% | 21.43% | -4 |
| S10 | 2 | Kameron Michaels | 9.09% | 27.27% | 27.27% | 36.36% | -3 |
| S01 | 3 | Rebecca Glasscock | 16.67% | 33.33% | 33.33% | 50% | -2 |
| S02 | 4 | Tatianna | 11.11% | 22.22% | 22.22% | 33.33% | -2 |
| S08 | 4 | Chi Chi DeVayne | 12.5% | 25% | 25% | 37.5% | -2 |
| S14 | 1 | Willow Pill | 7.14% | 7.14% | 14.29% | 14.29% | -2 |
A couple of names stand out. Darienne Lake has the lowest “Dusted or Busted” score of any contestant with a top four finish. In fact, she finished bottom or low in six of her 10 competitive episodes. The distance between her and the next lowest scoring top four performer by “Dusted or Busted” score (Courtney Act) is seven points.
Several names will be familiar and unsurprising entries on this list, thinking especially of Shannel, Jujubee, and Tatianna. Jujubee emerged as the queen of the read and the lip-sync assassin of Season 2. She was in the bottom two three times and sent home Sahara Davenport, Pandora Boxx, and Tatianna. No matter, bottom two performances are still penalized heavily in this scoring system. Tatianna, likewise, is in the bottom 10 in this metric. From my outside reading of how fans interpret the show, Tatianna was perhaps raw in Season 2—apparently only 20 years old at the time of filming. She was excellent in Season 2 of All-Stars, though. It is interesting to see two of Season 2’s top four in this list, though.
Kameron Michaels is the only No. 2 finisher to appear in this top ten. Fans of the show will note she mostly played it safe but, as the competition whittled down, otherwise “safe” performances put her in the bottom two. The interesting anecdote to emerge from that, however, is she appears to have the most consecutive “shantays” in lip-sync battles. In four-straight episodes, she shantayed in lip-syncs against Eureka O’Hara (a double shantay), Monét X Change, Miz Cracker, and Asia O’Hara. Do note that lip-syncs are selection effects. Kameron’s final lip-sync in that run was also a semifinal. Further, RuPaul is generally unforgiving of multiple, consecutive appearances in the bottom two (see: Alyssa Edwards [Season 5], Akashia [Season 1]). However, that four-episode run for Kameron Michaels is an all-time best and likely won’t be matched, given the nature of the show and the peculiar string of those lip-syncs.
Detox’s entry into this list is one of those head-scratchers that makes sense upon further review. Detox can match high-concept looks with great comedy, but that and her top three performance in All-Stars 2 belie that her performance in Season 5 included only one win and four appearances in the “low” or “bottom” categories.
Jackie Cox’s entry into this list does hurt a little, the extent to which she was the performer I had predicted to win the season. Alas, she had no wins and three appearances in the bottom two. That she had a “high” in four of her first five episodes offset much of that.
Which Contestants Were “Robbed” in Their Season?
I added this table after Season 11 ended because the selection of the champion is arguably a bit controversial. Not only does Yvie have the lowest “Dusted or Busted” score of any champion in a given season, but the queen she beat in the finale, Brooke Lynn Hytes, had a “Dusted or Busted” score a full three points higher. In fact, a latent variable analysis that I provide below will contend Brooke Lynne Hytes had one of the best seasons of any performer in the show’s herstory.
This would not be the first time a queen was “robbed” from winning her particular season (at least, if that’s how you want to spin it). Long-time fans of the show probably know Ru started the first season with the idea of crowning BeBe Zahara Benet at the end, forgetting along the way that it meant Nina Flowers had a better season and finished second. The most prominent case of this might have been Shea Couleé, who entered the semifinals as the top performer in that season and was bulldozed in the semifinal by arguably the best individual lip sync in the show’s herstory. Sasha Velour deserved to advance on the merits of the lip sync but it did mean Shea Couleé, who had arguably the third best run in the show’s herstory to that point, did not snatch the crown.
There are a few cases I show below where an individual performer had a higher “Dusted or Busted” score than the eventual winner that season, with more of them coming in more recent seasons. All have unique situations. Nina finished second despite having the overall better record than Bebe Zahara Benet, but Ongina was woefully underplaced in her season. She too had a better “Dusted or Busted” score than the eventual champion, but finished in fifth place. Shea Couleé had arguably the best season run in the show’s herstory but was eliminated in the semifinals. More recently, Brooke Lynn Hytes can now boast the biggest point differential in show herstory over an eventual champion. Her three-point cushion over the eventual season champion may not be topped.
| Season | Contestant | Rank | Number of Wins | Number of Wins for Champion | D/B Score | Champions's D/B Score |
|---|---|---|---|---|---|---|
| S01 | Nina Flowers | 2 | 1 | 2 | 4 | 3 |
| S01 | Ongina | 5 | 2 | 2 | 4 | 3 |
| S09 | Shea Couleé | 3 | 4 | 2 | 9 | 8 |
| S11 | Brooke Lynn Hytes | 2 | 3 | 1 | 5 | 2 |
| S12 | Gigi Goode | 2 | 4 | 3 | 7 | 6 |
| S13 | Gottmik | 3 | 3 | 5 | 9 | 8 |
| S13 | Rosé | 3 | 3 | 5 | 9 | 8 |
| S14 | Lady Camden | 2 | 3 | 1 | 4 | -2 |
| S14 | Angeria Paris VanMicheals | 3 | 2 | 1 | 0 | -2 |
| S14 | Bosco | 3 | 3 | 1 | 4 | -2 |
| S14 | Kornbread (The Snack) Jete | 12 | 1 | 1 | 2 | -2 |
One other metric for classifying “robbed” queens is to locate those queens who 1) finished outside the top four in a season but 2) had a higher “Dusted or Busted” score than the lowest-ranked performer to land in the top four. There are 44 such instances in the data, but much of that is in Season 6 because Darienne Lake had such a low score by the end of the season that even contestants like Gia Gunn and Laganja Estranja had comfortably outperformed her. The table below subsets that list to just the cases of performers who had the highest such difference in a given season and arranges them by largest difference.
| Season | Contestant | Rank | D/B Score | Lowest D/B Score in Top 4 | Lowest Ranked Top 4 Queen | Difference |
|---|---|---|---|---|---|---|
| S06 | BenDeLaCreme | 5 | 3 | -6 | Darienne Lake | 9 |
| S01 | Ongina | 5 | 4 | -4 | Shannel | 8 |
| S02 | Jessica Wild | 6 | 2 | -5 | Jujubee | 7 |
| S14 | Kornbread (The Snack) Jete | 12 | 2 | -4 | Daya Betty | 6 |
| S04 | Willam | 7 | 3 | -1 | Latrice Royale | 4 |
| S05 | Ivy Winters | 7 | 0 | -4 | Detox | 4 |
| S05 | Lineysha Sparx | 9 | 0 | -4 | Detox | 4 |
| S07 | Katya | 5 | 4 | 0 | Pearl | 4 |
| S10 | Miz Cracker | 5 | 1 | -3 | Kameron Michaels | 4 |
| S08 | Thorgy Thor | 6 | 1 | -2 | Chi Chi DeVayne | 3 |
| S08 | Acid Betty | 8 | 1 | -2 | Chi Chi DeVayne | 3 |
| S12 | Jan | 7 | 1 | -1 | Jackie Cox | 2 |
| S09 | Valentina | 7 | 2 | 1 | Peppermint | 1 |
| S09 | Eureka O'Hara | 11 | 2 | 1 | Peppermint | 1 |
| S11 | Plastique Tiara | 8 | 2 | 1 | Silky Nutmeg Ganache | 1 |
There should be some care in interpreting this table. I don’t agree with all of it (e.g. I’m on the record as being a big Kameron Michaels fan). Also consider that Eureka O’Hara and Lineysha Sparx had fewer episodes on which they could’ve accrued “Dusted or Busted” score deductions and these metrics are largely driven by the number of contests in which a queen appears. Yet, this table offers substantive support to the contention that Darienne Lake advancing over BenDeLaCreme in Season 6 was almost unforgivable. Further, Ongina was woefully underplaced in Season 1. Also, Acid Betty should’ve been on more episodes.
A Simple Item Response Model for Ranking All Contestants
Finally, I decided to run a simple graded response model on the data for all contestants. The graded response model includes the number of performances in which the contestant won, won or scored high, or was in the bottom.2 I also include the contestant’s final rank for the season and the “Dusted or Busted” score. Conceptually, these polytomous measures of a contestant’s performances are judges of a contestant’s ability based on discrete scale. This is obviously rudimentary, and someone more versed in IRT modeling will balk at treating the “Dusted or Busted” score in this way, but the model ran and I’m not submitting it for peer review and I don’t have time to invest in a more comprehensive model. Your critiques can sashay away.
The top 25 participants on this metric are listed below, with accompanying standard errors around the latent estimate.
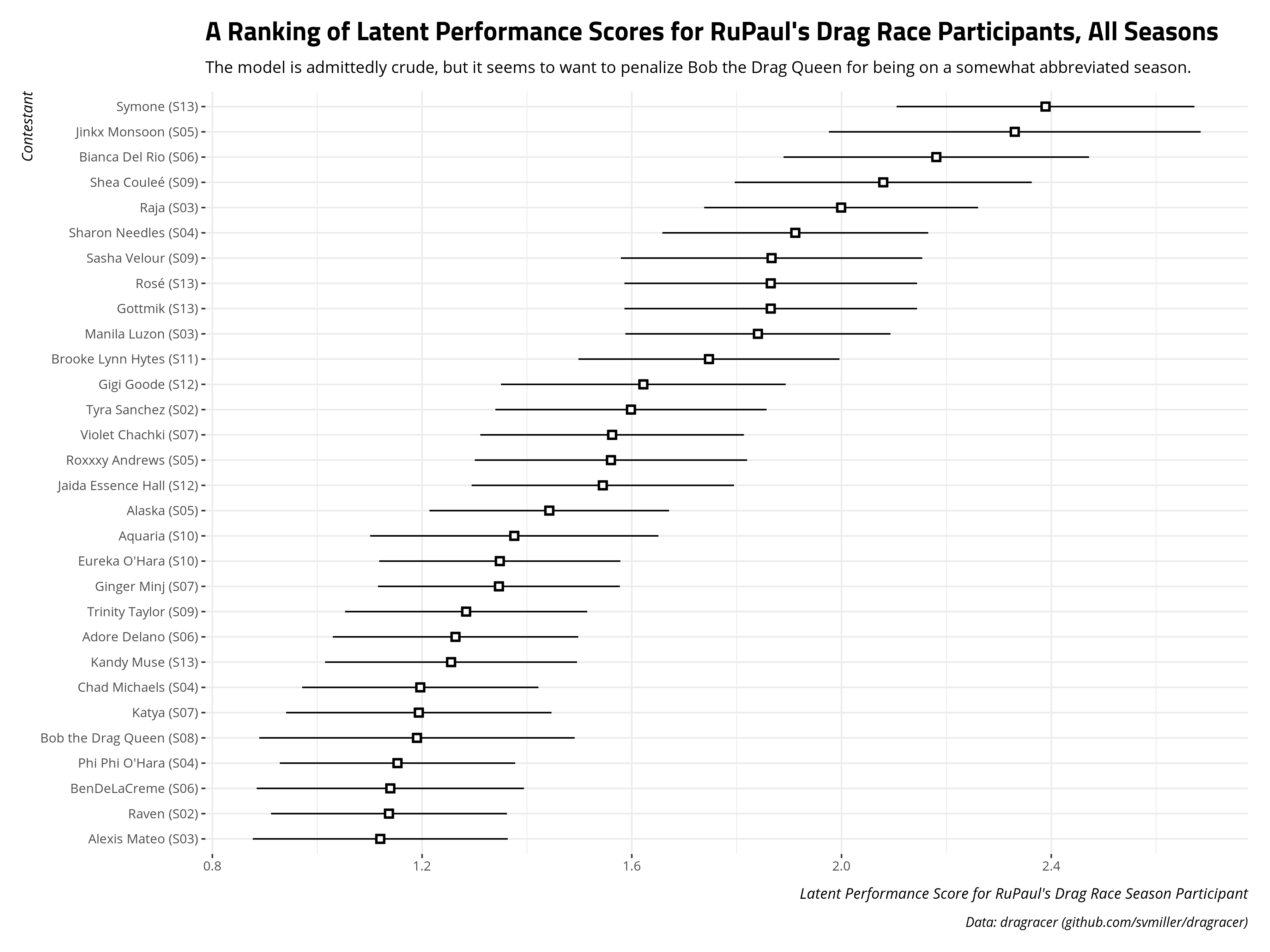
Fans of the show are free to read into this what they want. Several Season 13 scores are going to be functions of those first three episodes, which will artificially prop up some scores even if (I think) they were uncompetitive. I’m not too invested in what this demonstrates, but a few things are worth mentioning as quick hitters.

- She went home.
The model wants to downweight Bob the Drag Queen for being on an abbreviated season. She’s not the lowest-ranked winner on this list; in fact: Bebe Zahara Benet is not even on it. I don’t think fans of the show hold Bob in low regard. Her snatch game, always an important metric, is among the best. However, metrics for evaluating contestants focus on raw counts (e.g. wins, highs, etc). Toward that end, being on an abbreviated season hurts Bob’s rankings.
BenDeLaCreme and Katya are the only contestants without top four finishes on this list. This is a case where a model might tell you something that’s intuitively true, but probably not implied by what you thought from the inputs. In other words: these two are great. Katya could’ve won All-Stars 2 and the only reason BenDeLaCreme didn’t win All-Stars 3 is because she chose not to win it.
Conclusion: As Hot Takes
I don’t have much to conclude, but I do have a few #takes that I’ll offer as heaters here.
Assorted Season 1-10 🔥 Takes
- The scorecard is pretty clear Tyra Sanchez deserved to win Season 2, but I bet RuPaul wishes she could go back and do that one again.
- Kameron Michaels should’ve won Season 10. Hey, I didn’t say these takes were good, just that they were hot.3
- Sasha Velour needs a street named after her in Urbana. Hell, next-door Champaign had a street named after REO Speedwagon when I was living in that city. Why not Sasha Velour for Urbana?
- Acid Betty needed more episodes on Season 8. Her three high performances in the first three episodes push her up a lot of rankings for someone who otherwise landed No. 8 in a season.
- I would’ve put Aquaria as a bottom instead of Monét in episode 10 of Season 10. That would’ve put Aquaria, the future winner of the season, in front of the grim reaper of lip-syncs (Kameron Michaels). And, yeah, there’s no way RuPaul would’ve sent Aquaria home instead of Kameron Michaels, but the thought experiment is fun.
- I feel most scoring metrics for RuPaul’s Drag Race should include a category that awards 10 points to a contestant if she is able to check the box of “is Alyssa Edwards.” I think that’s appropriate.
- I am compelled to support Nina West in Season 11 because she is from Columbus. I will disregard any critiques of her as wrong as a result.
Season 11 🔥 Takes
Btw, nailed it. This was from February.
Hot and maybe only RuPaul's Drag Race Season 11 #take for a while: I think this season Ru goes hunting for a "mid-market" winner after three-straight NY-based winners. Lot of options for that this season. Heart says @NinaWest (O-H...). Gut says @OddlyYvie (of Denver).
— Steven V. Miller (@stevenvmiller) February 28, 2019
Jaymes Mansfield might appreciate this reference, but Silky for me was the first performer in the show’s herstory to have what pro wrestling fans call “X-Pac Heat.” There have been other villains in the show’s herstory you want to see vanquished or defeated. Phi’Phi O’Hara (Season 4), Roxxxy Andrews (Season 5), and The Vixen (Season 10) come to mind here as performers who took on a villain role but were still enjoyable to watch the extent to which a viewer wanted to see some measure of comeuppance. However, like the canonical case of X-Pac, I didn’t want to see Silky get her just deserts. I just wanted her off my television so I could enjoy the other performers.
I think Chris says it best here. Nina was great on Season 11 because her character on the show augmented other performers around her (prominently Brooke in the L.A.D.P. challenge). Silky just sucked up and rerouted the energy in the room in a way that doesn’t make for good television and isn’t compelling to watch.
Trying to be a Nina West in a Silky Ganache world. (Be brave enough to be kind)
— Chris Skovron (@cskovron) April 20, 2019
Not the first to make this observation, but this would be the first winner who lip-synced after Snatch Game. It was going to be the case no matter if Ru had gone with the Brooke edit or the Yvie edit.
I’m hoping Yvie’s win offers some pause for future performers who think the path through the finale is to make compound reveals. Yvie’s final two lip syncs were light on reveals (“Free Britney” in the first and the backward head reveal in the second). Contrast that with the compound reveals that Silky had in the lip sync that made no sense and were poorly timed. One tells a story through the song. The other is mindless theatrics. One works better than the other.
That said, Brooke’s final lip sync reveal was hilarious. I love a good fourth wall break.
Both of Silky’s wins were cases where I thought it was clear Nina had the better main challenge performance and runway look. Nina should’ve received those two wins instead. That would put Nina West at four wins on the season and would have made it almost impossible to deny her the crown. My apologies to Shea Couleé.
Also, political scientist speaking, Silky’s explanation for why she registers as a Republican was the dumbest thing I’ve heard an educated person say on that show. The rationale behind what she said was basically nails on a chalkboard as I heard it.
I’m still a bit apoplectic that none of the judges understood or got Nina’s Ohio flag dress.
Ra’Jah O’Hara has the distinction of being tied with Carmen Carrera for the worst ever D/B score in the show’s herstory (-8).
I thought this season took a while to get going. With 15 queens in the mix, the space seemed kind of crowded and it took about four or five episodes to figure out who some of these queens were and identify with them and their craft.
Season 12 🔥 Takes
Season 12 season was cursed; I’m not sure there’s a more polite way of putting it. The season started on the awkward note of one of its marquee performers allegedly catfishing men and deceiving victims into doing things that are unprintable here. The performer in question appeared to confess to doing it early in the process, and was subsequently disqualified. Making matters worse: most people knew in advance she was going the distance in the season. What resulted was an awkward bumper at the start of every episode and even more awkward post-hoc edits to minimize her screen time as much as possible. Whatever story arc would’ve emerged from the season was gone. The COVID-19 pandemic topped all this off with a taped finale in front of no live audience. These are no fault of the show or the undisqualified performers. It was just a cursed season.
I’m probably in the majority that Michelle’s critiques often come off as harsh for harsh’s sake, but she was 100% on point for calling this performer “selfish” after going 17 minutes for a performance that was supposed to be five minutes. That RuPaul appeared to brush it off seems kind of surprising. In hindsight, Ru probably wishes she used that moment to jettison the performer then and there. Basically, going over three times the allocated time sucked the entire energy out of the room and exhausted the audience. It made the room want to go home before Jaida sent them home. It’s exactly the kind of selfish behavior that reveals something very unflattering about the performer who does it. If I were RuPaul, and not knowing anything about the catfishing controversy to follow, I would’ve used that opportunity to send her home after a pro forma lip-sync. I’m that serious about it too. She basically broke the rules for the challenge three times over and got a pass for it.
Cursed nature notwithstanding, I thought the finale was very well done. It’s tough—even impossible—to get the full atmosphere of a drag performance without a live audience, but the limitations of the pandemic allowed for more creativity from the top three performers. The individual lip-syncs allowed them more opportunity for artistic expression.
Further, I thought Season 12 was more enjoyable than Season 11 with all that said. The individual performers stood out more and I got to know more about them and their drag. This was a cursed season, but a good season.
This was a unique situation but I hope Season 13 returns to a “top four” format in lieu of this season’s top three format. A “top four” with a semifinal makes it more “sports-like” despite its clear nature as a reality TV show, which makes it more enjoyable for me at least. Again, unique situation. I bet they’ll return to a top four with Season 13. I hope they do, at least.
I missed “World’s Worst” and apparently missed the broccoli thing. Sometimes you just have to let a “Miss Vanjie” moment happen organically. It’s fine if it doesn’t. Not every season needs one.
Every now and then, a queen comes out with a look that no one gets it and it bothers me to no end that no one got it. Last season, that was Nina West’s sparrowtail Ohio dress. This season, it was Crystal Methyd’s “HIM” drag. How no one did HIM on this show before is crazy to me. It was perfect, and no one got it.
I knew she wouldn’t win, but of the remaining three, I was hoping it’d be Crystal Methyd’s night. Her style of drag is basically watching children’s programming in a k-hole. Her Bert and Ernie makeover is the most genius WTF thing I’ve ever seen on the show.
RuPaul tried to rename/rebrand three contestants on the season. Jan (Sport) and Britta (Filter) had their personas truncated for it. I get RuPaul doesn’t want to invest time or money into licensing the full names for the show, given the evoked set, but it means Jan (Sport) and Britta (Filter) are behind an 8-ball for it from the very start. Basically, can you imagine any winner on this show being minimally named “Jan?” At least “Alaska” (Thunderfuck 5000) doesn’t sound like the name of a 5th-grade mom running the bake sale for her son’s flag football team. The performers behind both names may exchange that possibility of winning $100,000 for the increased exposure and prospects for long-term earnings the show provides—and that’s a fair trade-off if the performers have a long-term vision and explicitly consent to this—but it doesn’t make any less awkward for the viewer. The worst case was probably RuPaul’s season-long crusade to rename Heidi N Closet. What emerged from this season-long crusade comes off kinda cynically. RuPaul is trying to pick Heidi from the outskirts of even the smaller drag centers and rebrand her in Ru’s own image, disregarding how Heidi sees herself and would like to promote herself. This makes RuPaul more a “savior” and less a platform where independent artists can express themselves. I mean, it’s Ru’s show, and RuPaul is clearly a greater resource for drag tips than me. It’s just… awkward. Let Heidi N Closet be Heidi N Closet, and let Jan Sport be Jan Sport too.
I really dug Jan Sport. That Gigi Goode got her Madonna Rusical win was one of the biggest main-challenge-winner head-scratchers in the show’s herstory. At least she got a meme out of it, I suppose? Either way, I hope she cleans house on whatever All-Stars she enters… as Jan Sport. Trixie was allowed to be Trixie Mattel; why can’t Jan be Jan Sport?
I’m still gobsmacked that Rock M. Sakura was a second-out. At least “first-outs” like Victoria “Porkchop” Parker or Vanessa Vanjie Mateo get some kind of distinction and recognition from the fanbase. Fans work hard to remember those. Some of those first-outs are legitimately great, like my girl Jaymes Mansfield. How many second-outs can you recall off the top of your head? How many of them are Rock M. Goddamn Sakura? Rock is basically the result of Kim Chi and Trixie Mattel having a baby, but the relationship didn’t work out and instead Katya emerged as stepdad/mom to Rock growing up. While fans can connect Rock’s drag to other performers before her, she still emerges as a really unique talent and someone who needed way more time on the show.
Related: I’m not saying RuPaul has it out for the San Francisco drag scene, but I’m thinking it kinda loudly. Only two performers from the city—a city perhaps at the foundation of drag—have appeared on the show. Both were dumped early into the competition, and dumped unceremoniously.
I think I have a good intuition to what RuPaul wants to do in a given season. I called Yvie winning Season 11. My wife can attest that I had pegged All Stars 2 and All Stars 4 to be victory laps for Alaska and Trinity (still counts), respectively. I got it wrong this season. My intuition was Ru was looking for a “political” winner in the season preceding a presidential election. I thought that would be Jackie, and it was not. At least Jackie gave us the season’s best lip-sync.
Do I get partial credit for the season’s winner being the one who won the political challenge, though? For the three seasons that have preceded a presidential election (Seasons 4, 8, and 12), the winners of the season’s political challenge won the crown at the season’s end.
Season 13 🔥 Takes
This season had some promise at the onset but felt like a slog to finish. It didn’t help that Season 13’s longevity clashed with the restart of the second season of Drag Race UK. The latter was infinitely more enjoyable. As far as I’m concerned, Victoria Green is the uncrowned, people’s champion of Drage Race UK and probably Season 13 as well.
I do appreciate that Season 13 allowed for a few non-competitive episodes before sending the first performer home. Thus, the viewer got to see more of someone like Kahmora Hall that better showcased her drag before giving her the first-out label. And that’s good! Imagine the kinds of things we’d have seen from Kelly Mantle or Jaymes Mansfield if they had that opportunity as well. However, it just felt like a chore near the end. The season definitely did not need a double shantay.
Related, and at the risk of naming names, there is a subset of performer for whom “to spill the tea” and “to be honest with you” amounts to an ability to give criticism and not receive it. We all know those people and they’re not a whole lot of fun.
I think part of the issue was the show had two unfortunate problems that kind of undercut it as the season progressed. For one, the performers for whom we thought there was the most promise—thinking of Olivia Lux and Utica Queen—really ran out of steam near the end. In some cases, it amounted to a pivot into car-crash television for the show. Related, the performers who were abruptly eliminated became performers we wish we could see more. Denali especially stands out here. I could offer a similar comment about Elliott with 2 Ts and Joey Jay. Joey Jay, in particular, was a lot of fun to watch and Elliott’s dancing ability really showed.
For the life of me, I don’t understand why it became a theme of this season that Rosé tried to be “too perfect” or “too polished.” Like, what even is that? I’ll say this from my perspective. I’m a university professor who has endeavored my entire life to cultivate and develop my passions from my youth. I find things that interest me and I invest time and energy into knowing everything I can about them while trying to be as good as I feasibly can be at them. This ranges from what led me to get a PhD to other interests in things like luthiery and computer programming. I’m also a guy who has struggled my entire life with understanding how people work and how society operates. At some base level, I really don’t get it. I don’t understand how other people operate (beyond all things political, given my training). I’m also aware I can’t be an asshole and try to impose my will on others amid my confusion. Being a good, socially responsible person is in part about identifying contraints—things you cannot do nor say—and operating within them. These are constraints that emerge because saying or doing these things impose harm on others, if not yourself, and things fall apart pretty quickly if everyone violates these constraints and the end result makes everyone worse off. Toward that end, that’s really the only thing at some base level that made sense to me about living in society. If you’re a mindful person with good intentions, and the kind of person prone to analysis paralysis, it means you’re probably going to be super mindful of your Ps and Qs so that you don’t say something that accidentally makes someone uncomfortable. Few things give me hives quite like being misinterpreted, either because I did not know how to perfectly say what I intended to say, or because I spoke off the cuff and said something the wrong way that hurt someone. From my perspective, someone like Rosé was super relatable. She’s passionate about what she does. She’s (clearly) great at what she does. She’s also super mindful about what she says and she does as she focuses on her craft. I don’t know if she struggles with these things as well as I mentioned them, but those particular criticisms leveled against her—I’ll be polite—make zero sense. It was just a weird character arc this season, made even weirder that those were comments raised by both fellow performers and the show’s judges.
I don’t think it’s hyperbole to say Denali might be the most interesting contestant they’ve ever had, at least when combining the queen we see on television with the details of the performer behind the queen. Denali’s wiki has a whole host of things that I wish came up on the show or were discussed more.
-
The University of Alabama’s Center for Ethics and Social Responsibility produced a video about her experience that’s worth watching. ↩
-
I had also included the number of performances in the bottom or with a low mark. This factor didn’t load well and the model improved for its absence. ↩
-
But seriously Kameron should’ve won Season 10. ↩
Disqus is great for comments/feedback but I had no idea it came with these gaudy ads.